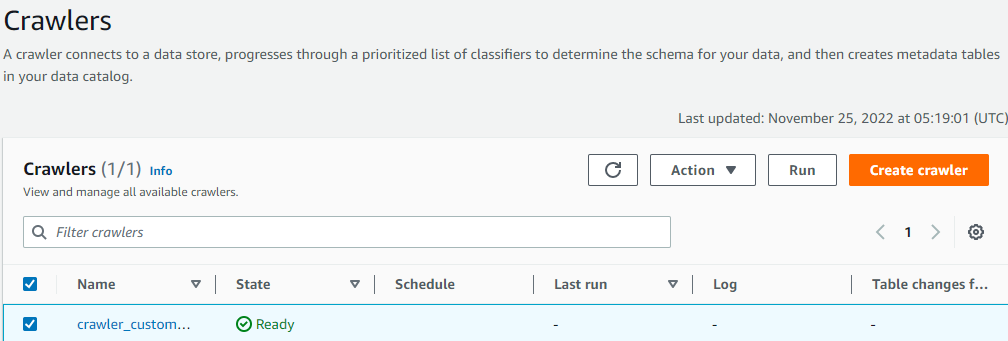
👋 Welcome to practice AWS Glue here with me.
AWS Glue provide Powerful functions for users,including building ETL pipeline,identify the data by specific user data schema.
we can use it to build the datalake too.One of the most important place is that Glue is serverless .It cost less and achieve it more.
In this Blog we gonna using AWS Glue to connect to data sources in Amazon S3. and then using Athena with AWS Glue.
Create S3 bucket sources
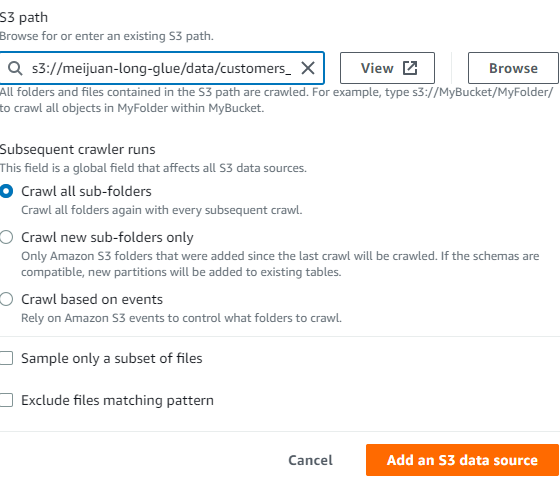
the data structure of S3 folder is
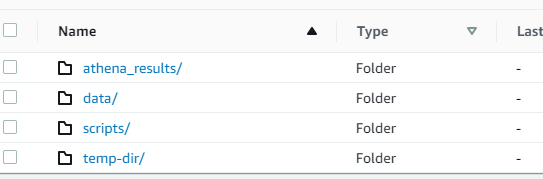
├── meijuan-long-glue
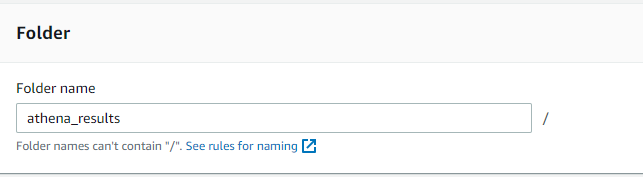
| ├── athena_results
| └── data
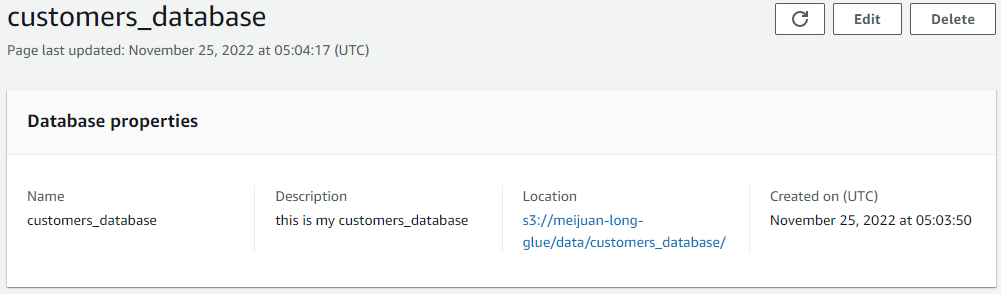
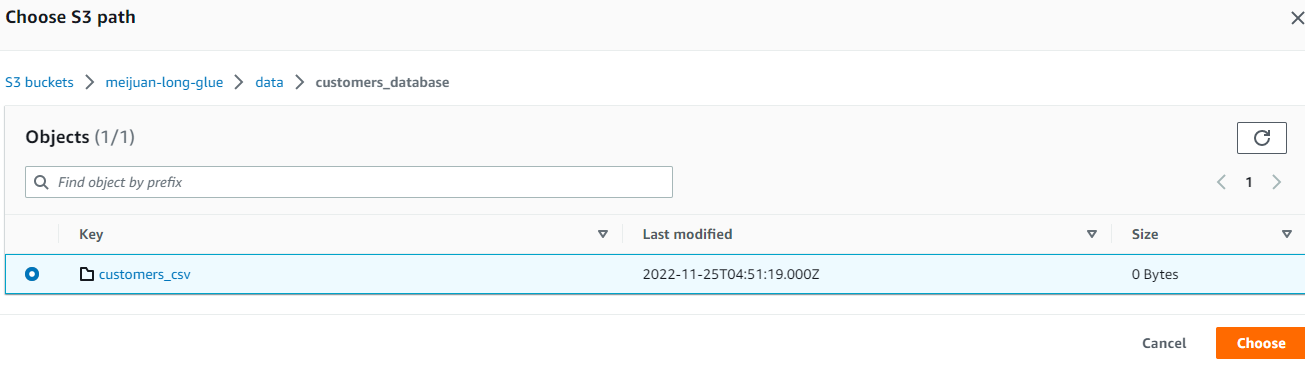
| | ├── customers_database
| | └── customers_csv
| | └── dataload=20221124
| | └── customer.csv
| ├──scripts
| ├──temp-dir
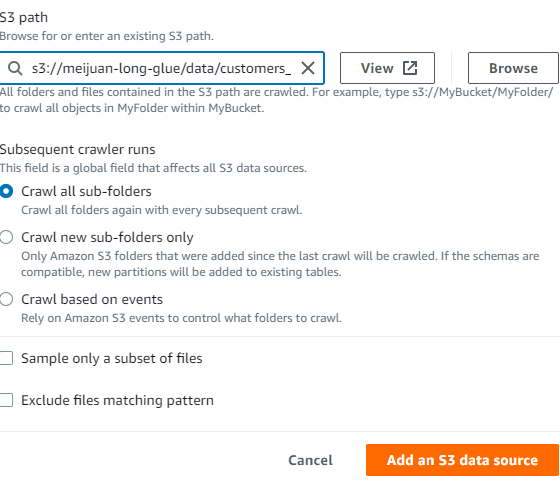
- new S3 bucket meijuan-long-glue

- create data folder in root path of bucket
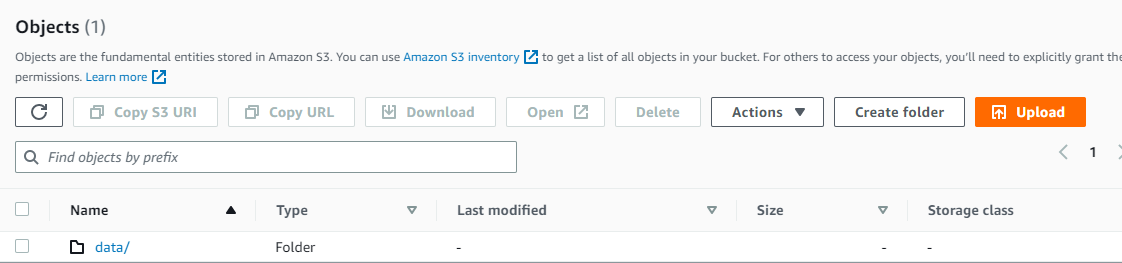
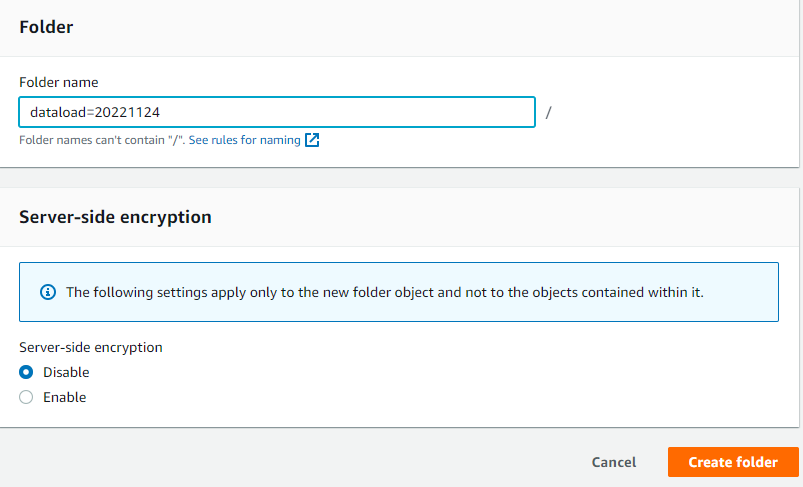
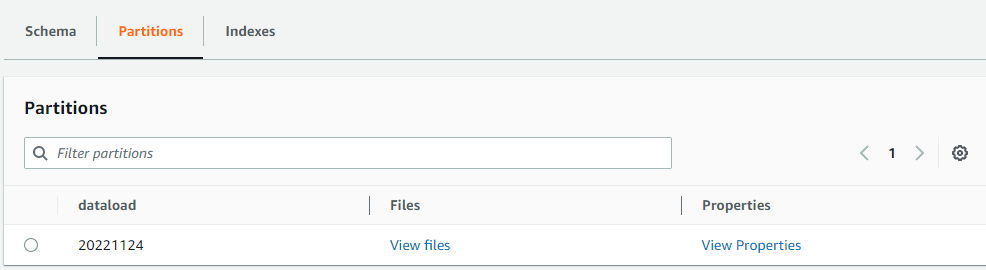
- create partition folder(dataloader=20221124) after create in the table folder
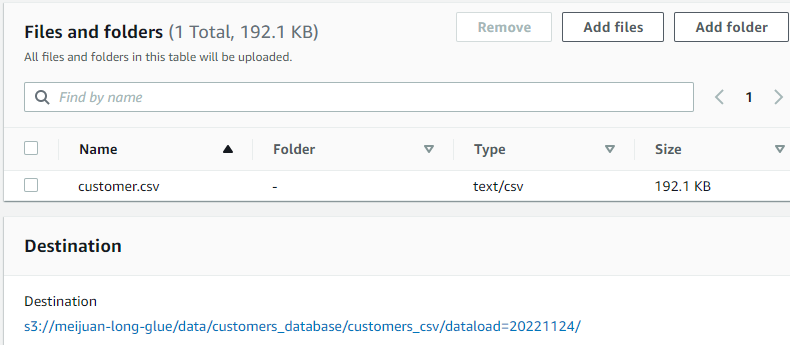
- upload the test file under the partition folder(dataloader=20221124)
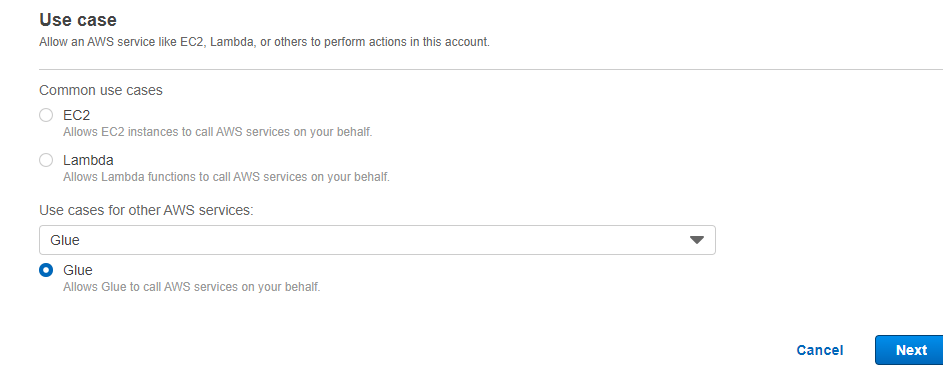
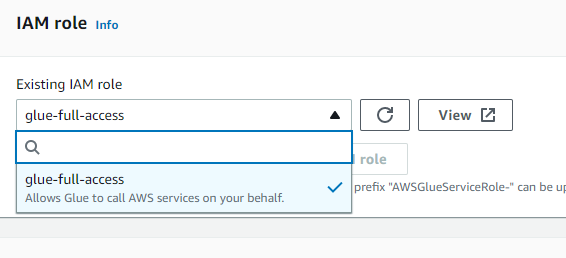
Config IAM ROLE
we need use this role for Glue access data in s3 or other service .So here I gave administratorAccess
- select Glue service when create the IAM role
- select administratorAccess
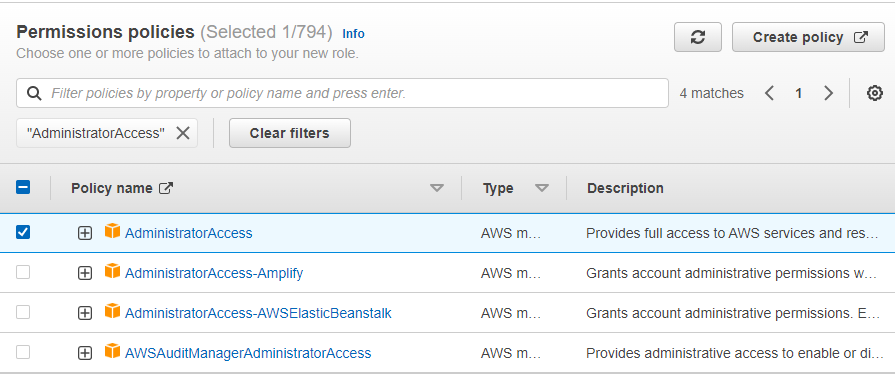
Config IAM ROLE
we need use this role for Glue access data in s3 or other service .So here I gave administratorAccess
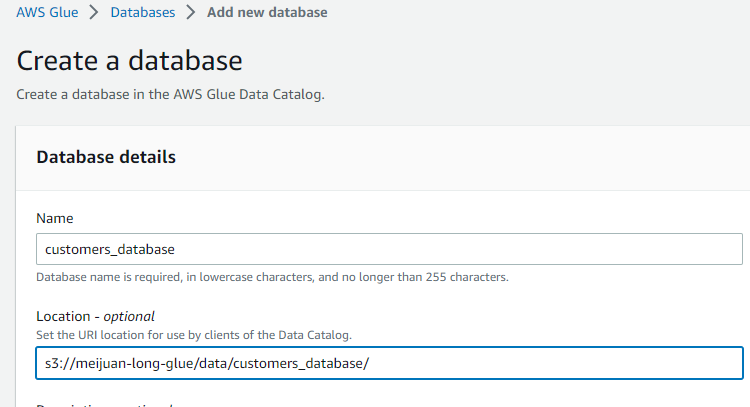
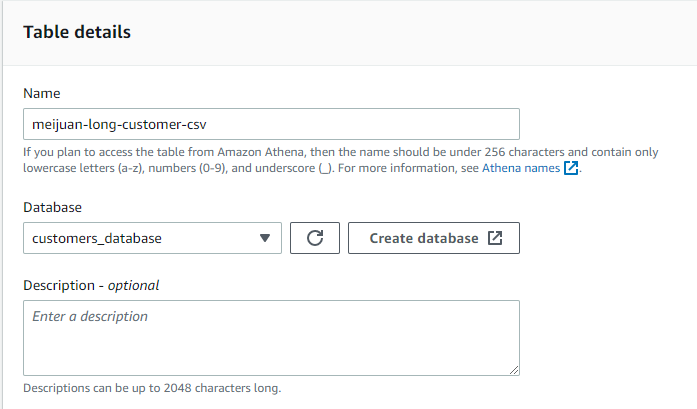
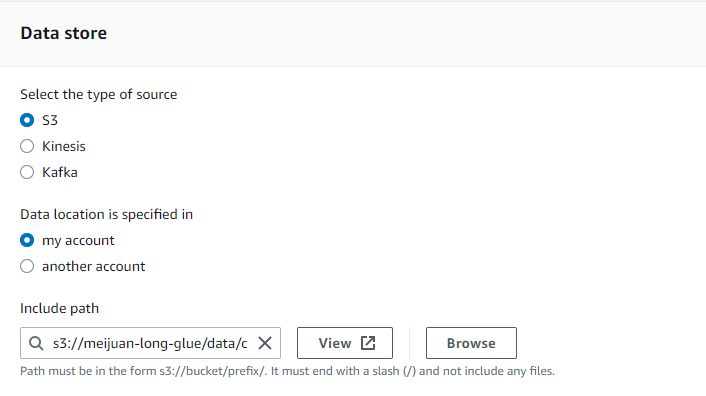
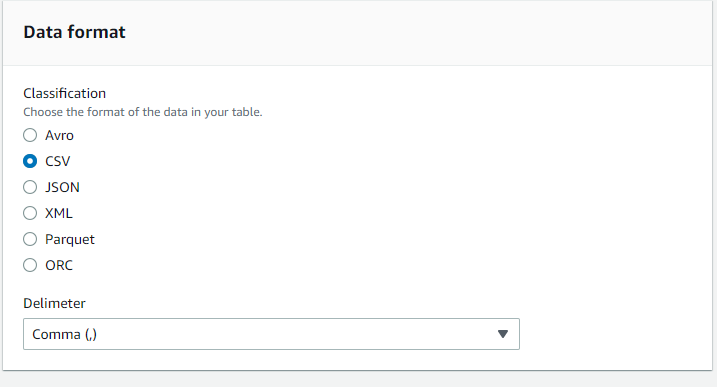
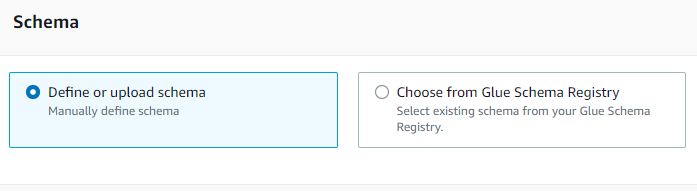
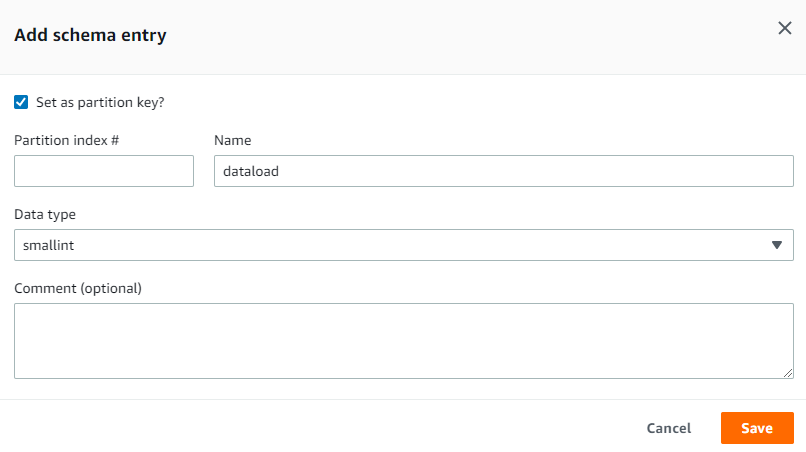
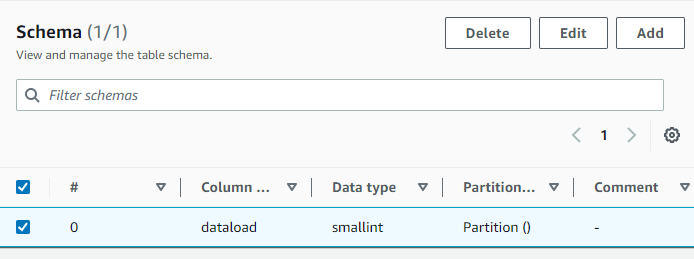
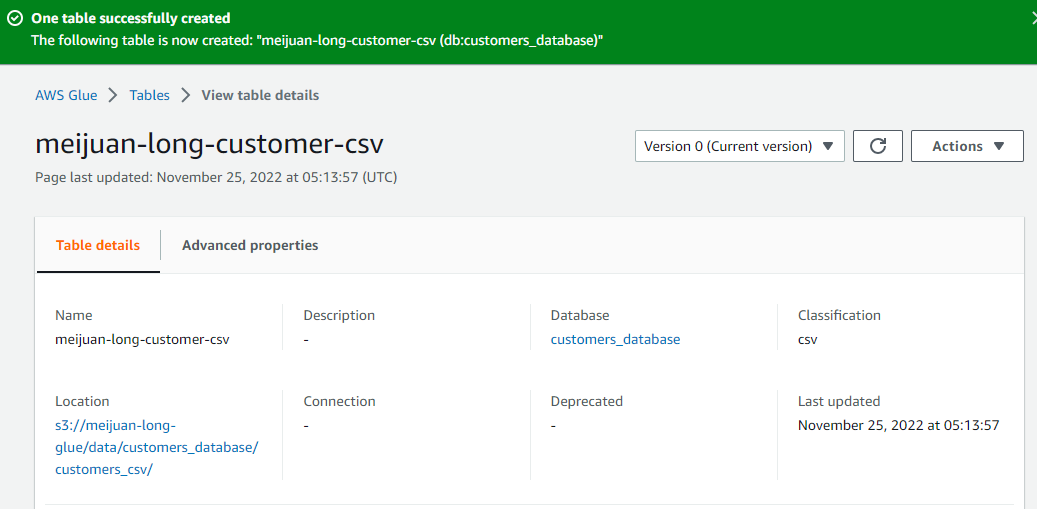
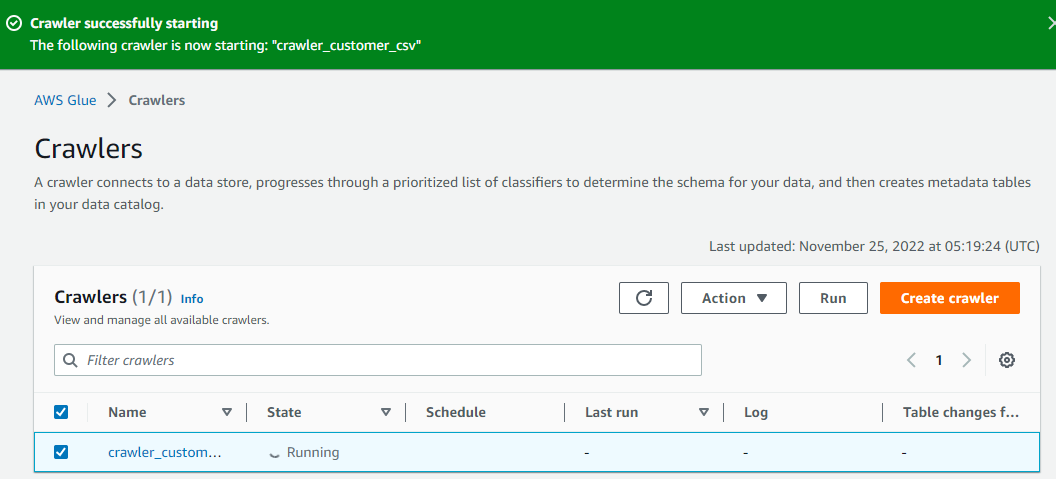
config athena
we need use this role for Glue access data in s3 or other service .So here I gave administratorAccess

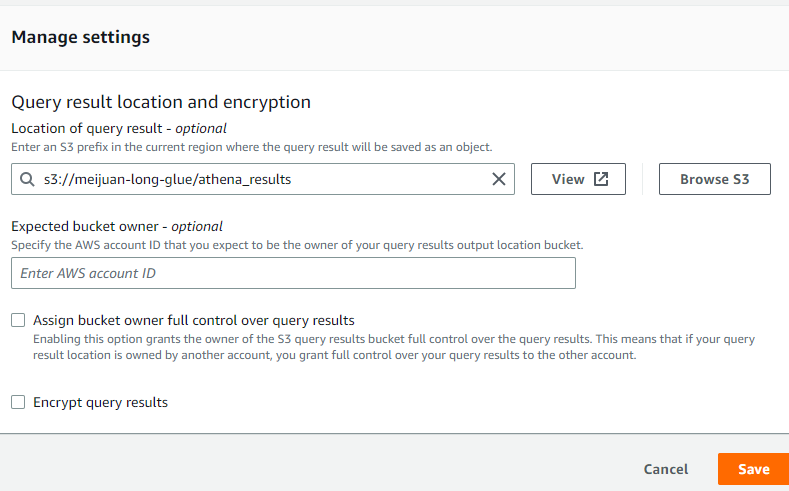
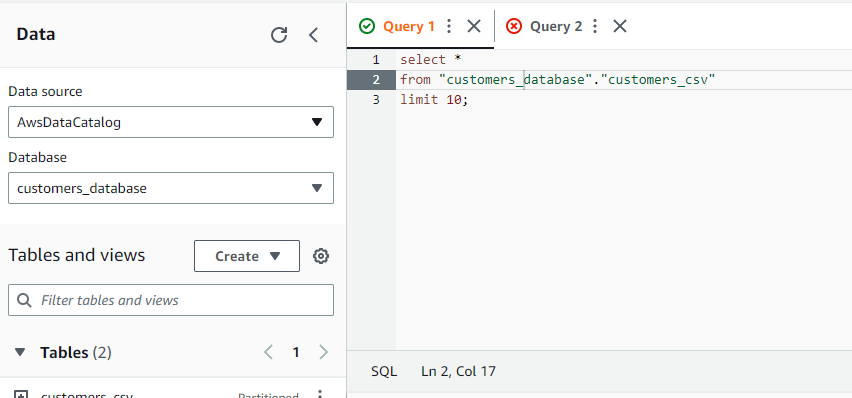
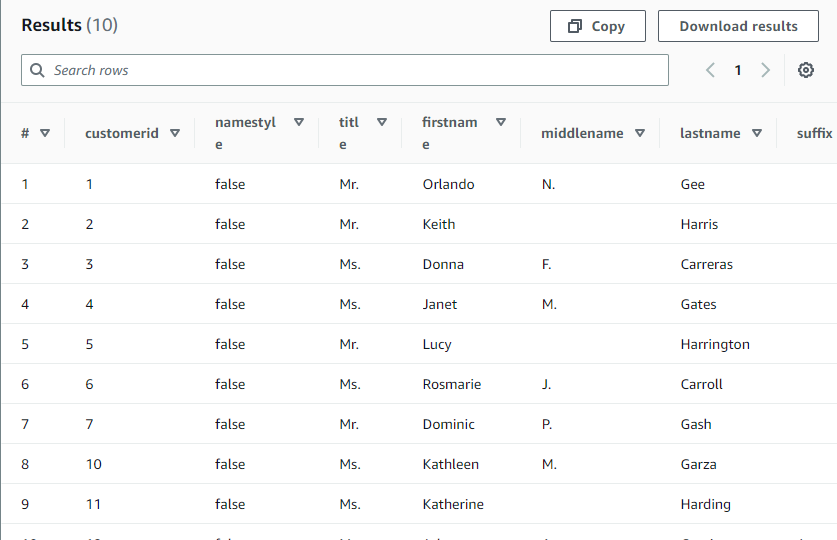
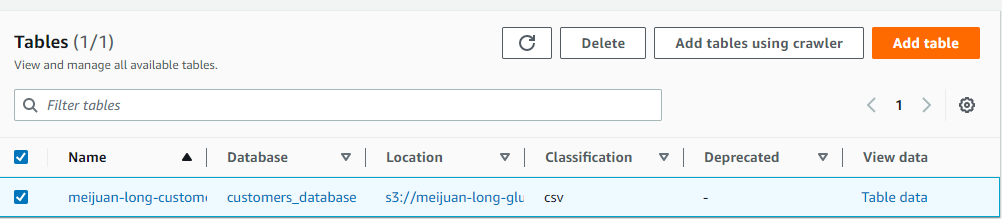
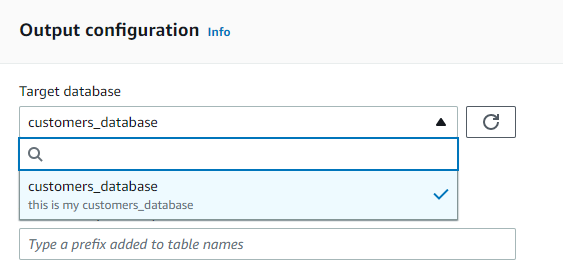
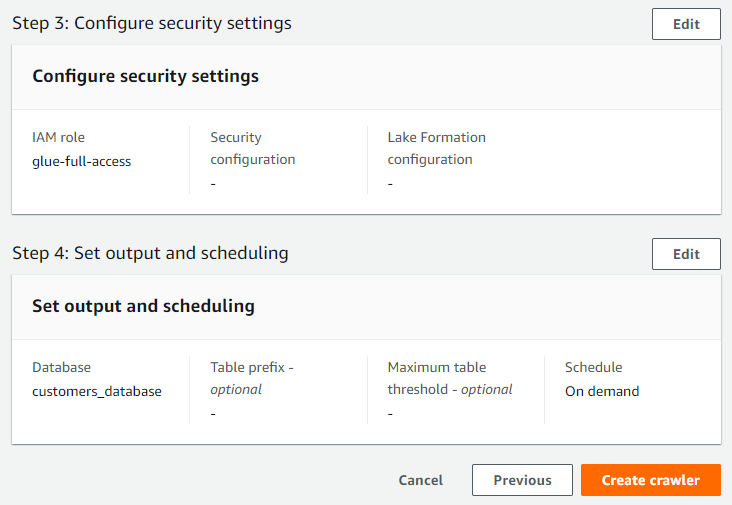
So After so long process,We have successfully manage the data in S3 to Glue.we have defined the schema by ourself and we can use athena to operate the data.the schema is stored in Glue,and the Data is stored in s3. It is pretty like hive framework.In have the data is stored in HDFS and the meta data is stored in Mysql table which is managed by hive.