About
Let me introduce myself.

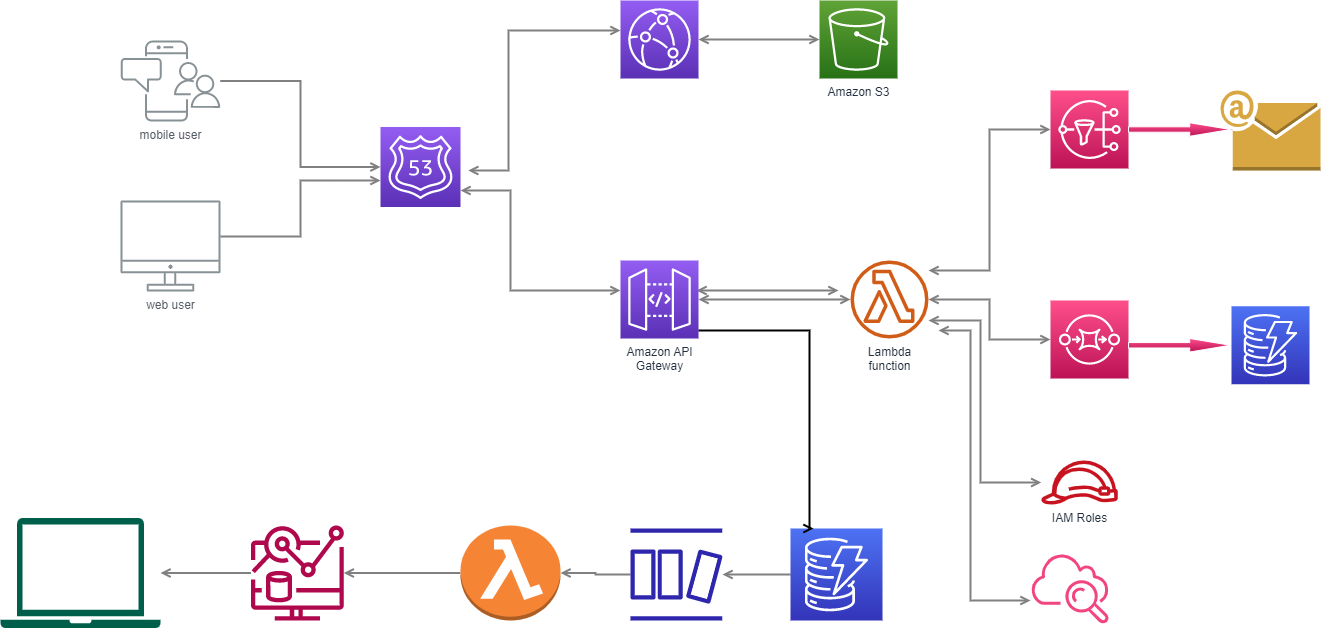
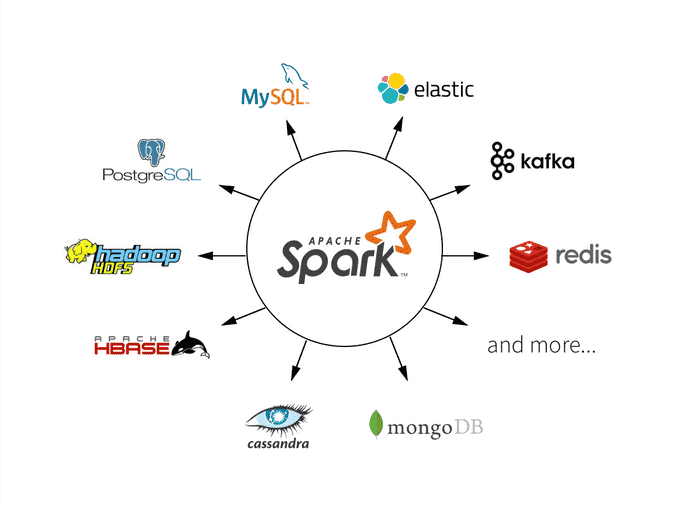
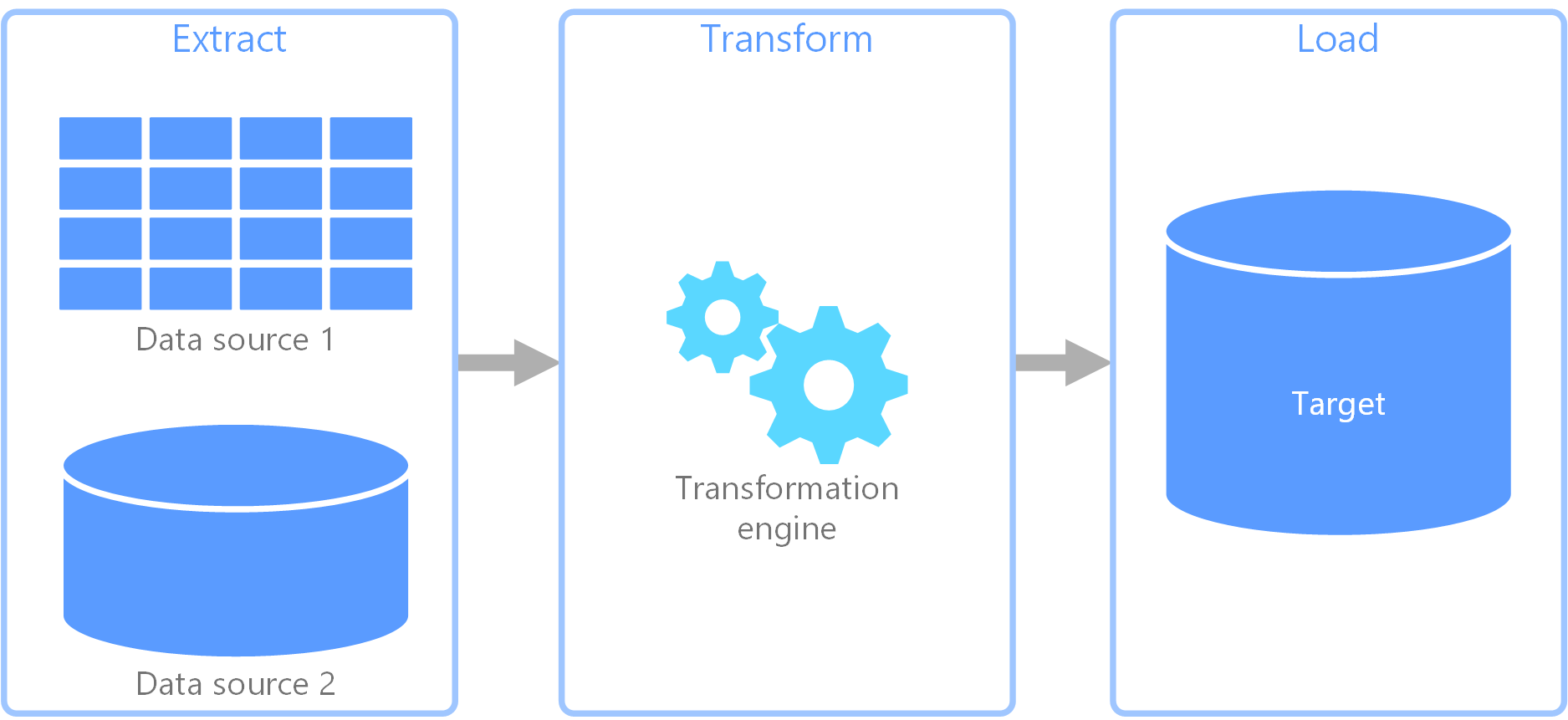
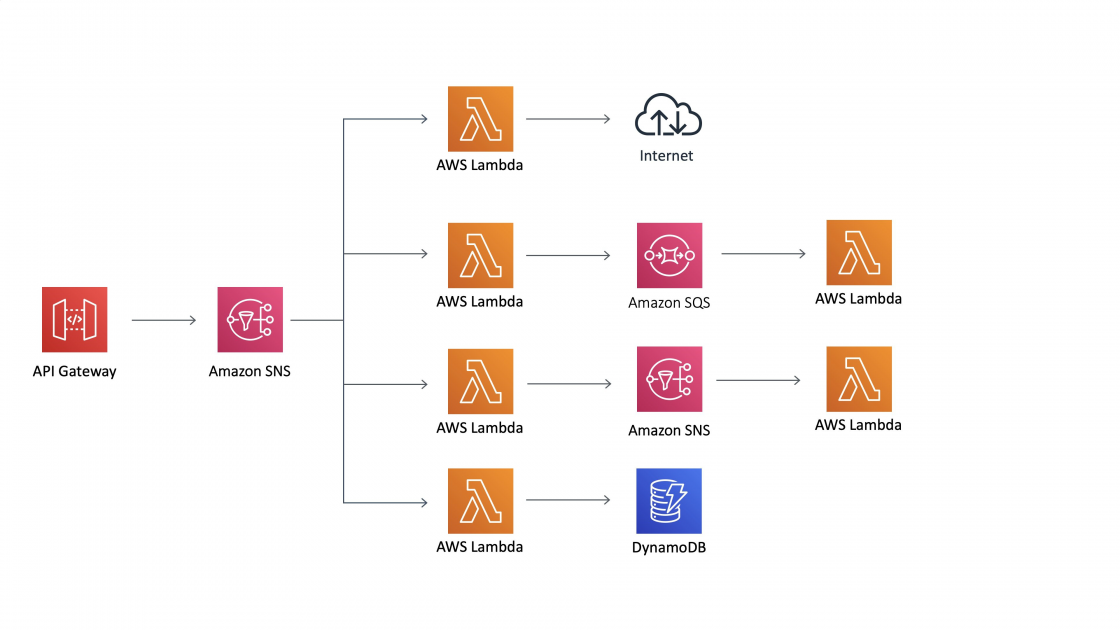
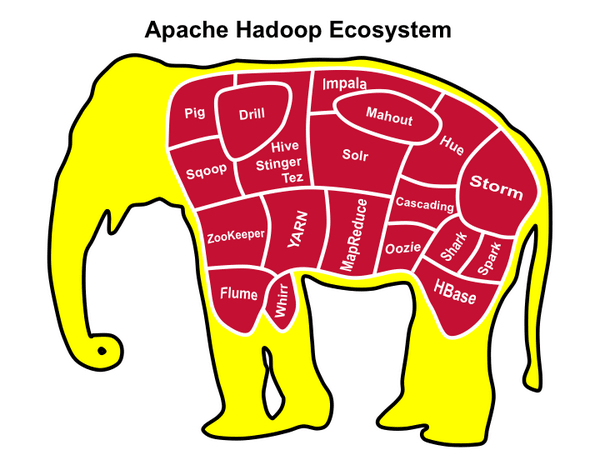
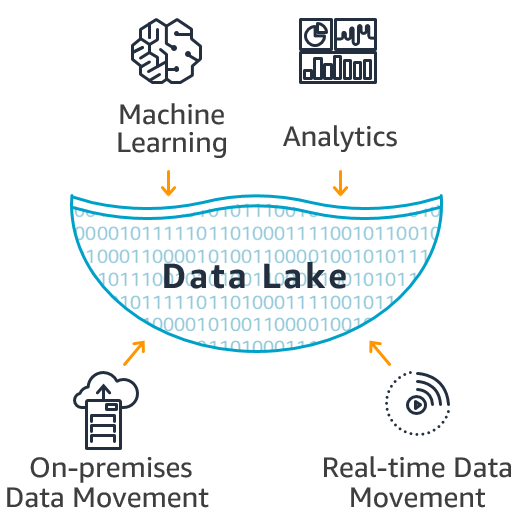
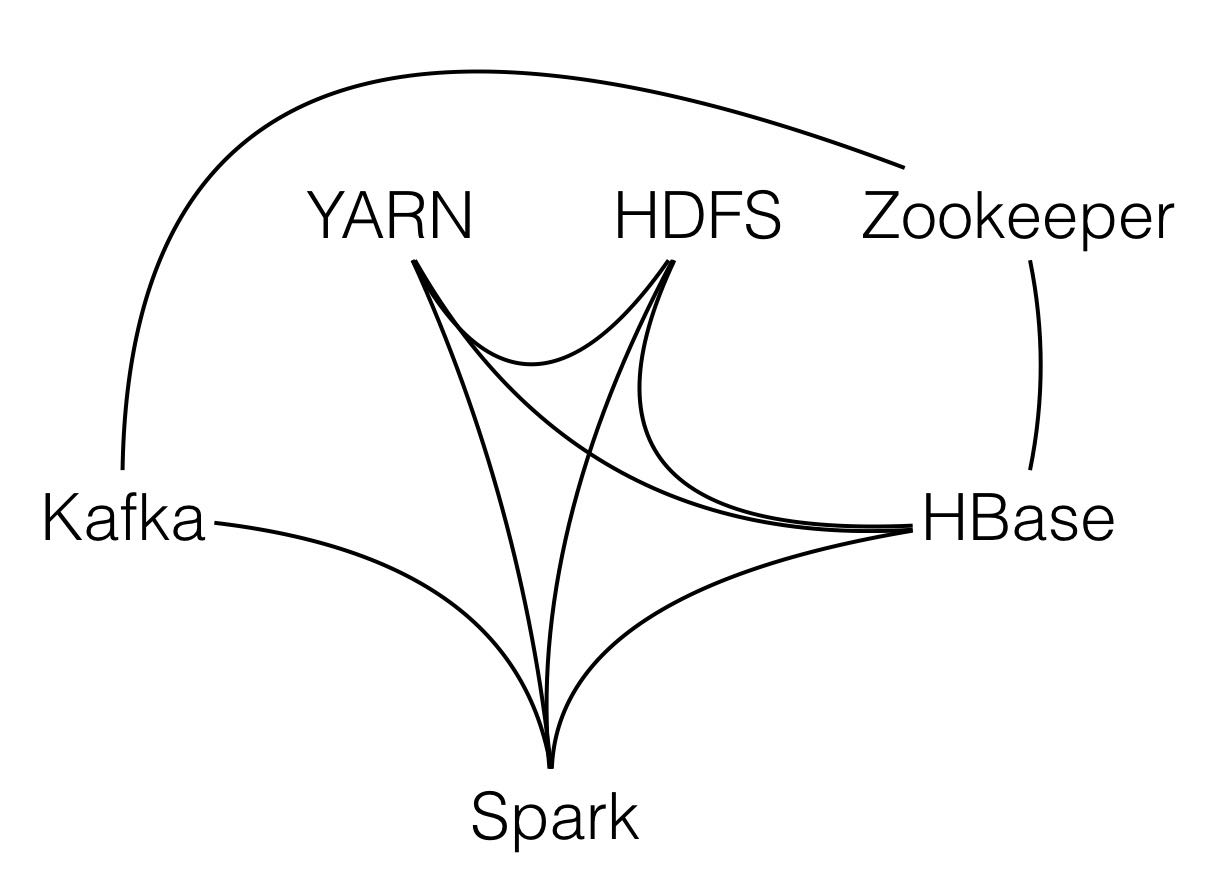
Over 5 years of professional IT experience in Design, Data Modeling, Development and Implementation of various client server and decision support system environments with focus on Big Data,and DatabaseApplications.
Profile
good level of experience in Core Java,J2EE technologies as JDBC,Servlets and JSP.
- Fullname: Meijuan Long
- Job: Big Data Engineer, Software Developer
- Website: www.meijuan-long.click
- Email: melissa.0.long@gmail.com